Completion requirements
6. Backup
6. Backup
Passiamo ad una componente fondamentale nella gestione del ciclo di vita del web server.
L’argomento è più complesso di quello che il nome evoca. Pertanto lo dividiamo in una prima parte dove vediamo di capite cos’è il backup e cosa si mette sotto backup. Successivamente vediamo quali tipi di backup esistono con i pregi e i limiti di ciascun approccio. Quindi vediamo un paio di soluzioni semplici di backup. Successivamente affronteremo la complessa questione della conservazione dei backup e chiuderemo con un piccolo excursus di confronto tra backup e disaster recovery.
6.1. Backup: cos’è
Il backup è semplicemente la copia di un file per riaverlo qualora l’originale scompaia per un qualsiasi motivo.
Il concetto semplice soffre diverse complicazioni quando guardiamo alla realtà dei nostri dispositivi di lavoro e ai server. Saltiamo a piè pari la questione dei dispositivi individuali e guardiamo ai server e ai siti web. Iniziamo pensando al lavoro che abbiamo fatto prima e diamoci l’obiettivo di fare il backup di PhpMyAdmin, Joomla e WordPress che abbiamo prima installato.
Fare il backup significa, dunque, copiare tutti i file che abbiamo messo nella web root (la directory /var/www/html ). Inoltre dobbiamo copiare anche i database associati a Joomla e a WordPress. Infatti i file di un CMS senza il database non funzionano.
Fermiamoci qualche istante e facciamo qualche considerazione fondamentale sui file e sui database.
File:
-
in primo luogo dobbiamo copiare insieme al file anche i permessi associati ai file.
Una prima difficoltà è legata ai programmi che copiano i file; non tutti i programmi copiano anche i permessi. Bisogna rilevare che tutti i programmi specializzati nel backup ormai salvano anche i permessi.
Questo, però, non risolve il problema. Infatti se restiamo sempre in server di tipo Linux, non è detto che il nuovo server abbia la stessa mappatura di permessi, di gruppi e di proprietari. Pertanto il file può conservare correttamente i permessi di sicurezza, ma l’UID 33, ad esempio, può essere associata ad un utente diverso rispetto al nostro nuovo server. In effetto domino questo produrrà problemi sul corretto funzionamento del web server che avrà problemi (anche potenzialmente bloccanti) nell’accede ai file, alle directory e a creare-modificare i file; -
un secondo problema rilevante è legato alle dimensione totali dei backup. Normalmente i file prodotti dai software di backup sono file monolitici. Il che, in linea di principio, significa che hanno dimensioni uguali alla somma totale di tutti i file che compongono il sito (o i siti). Rapidamente dai circa 250MB occupati con le attività sopra descritte, si passa a diversi GB (vi assicuro che velocemente si raggiungono le decine di GB). File di dimensioni così grandi sono facilmente copiabili con gli attuali dispositivi di memoria e le velocità di copiatura, ma la manipolazione (estrazione, compressione, ecc…) non è né scontata, né di facile gestione anche per PC di ultima generazione.
Fondamentalmente si modera il rischio e la complessità con software specializzati per il backup; -
come accennato sopra i backup occupano sempre molto spazio. Normalmente vengono compressi i file generati dai software di backup. Questo significa dimensioni finali ridotte, in modo da poterli collocare su un disco estraibile, piuttosto che su cassette a nastro. Ma ciò comporta anche tempi e capacità di calcolo superiori. Va tenuto presente che il processo richiede anche dello spazio swap durante la creazione-compressione dei file.
Se per un web server dedicato, come abbiamo fatto con le operazioni sopra descritte, l’operazione crea solo un rallentamento nel funzionamento con piccole noie per i navigatori, per server reali, dove hanno centinaia o miglia di accessi contemporanei, l’overhead può creare sospensioni di servizio e problemi nella creazione del backup;
-
il backup per essere tale non deve essere sul disco del server per ovvi motivi. Se il server si rompe si perde anche il backup.
Ciò non significa, però, che siamo sollevati dal dover calcolare anche uno spazio libero per i backup. Servirà soprattutto per il restore, ma anche durante la creazione dei backup stessi. In prima approssimazione, del tutto esemplificativa, dobbiamo tenere presente che lo spazio disco disponibile deve essere uguale o superiore allo spazio occupato dai dati;
-
un aspetto insidioso da tener presente sono i file volatili creati dai siti (anche dai semplici e popolari CMS Joomla e WordPress). Per una ragionevole economia di spazio non vanno copiati. Inoltre l’eventuale loro copia può creare problemi anche importanti nel restore. La difficoltà è legata al fatto che non esiste un solo standard di riferimento per tutte le varie soluzioni di siti web dinamici esistenti. Pertanto la configurazione del software di backup comporta anche un buon livello di competenza del tecnico che cura il server e/o il sito;
-
i backup che otteniamo devono avere alcune caratteristiche costanti (altrimenti non sono backup).
La prima è che devono essere su supporti di memoria diversi dal server e devono essere portabili (un disco esterno, una cassetta a nastro, ecc…).
Una seconda caratteristica è che devono essere criptati. Infatti se vanno in mano ad un estraneo non deve essere in grado di estrarli. Se avviene un accesso al contenuto di un backup c’è un accesso a potenziali dati riservati e, comunque, verrebbe a conoscere dati tecnici del sito come, nel nostro lavoro fatto fino qui, le credenziali di accesso al database.
Terzo elemento, di difficile gestione, il backup deve essere estraibile anche nel caso di guasto del sistema nativo di restore. Infatti se ci trovassimo nella situazione di un guasto o un incidente particolarmente grave del server, deve essere percorribile una via di restore alternativa. Di converso questo significa anche un adeguato livello skill dell’operatore e la conoscenza (o accesso) dell’operatore alle chiavi di decodifica;
-
l’ultimo scenario introduce un’ulteriore insidia che resta quasi sempre nascosta: la consistenza dei dati contenuti nel file di backup.
Invisibile a molti, ma i computer fanno errori nel copiare i file. Anche i supporti di memoria si possono corrompere per cause del tutto imponderabili. A volte gli errori o le compromissioni sono minime, ma usando file criptati e compressi possono impedire il restore di tutto il backup.
Questo significa che per un backup affidabile dobbiamo usare prodotti di qualità (il che si traduce in costi maggiori rispetto ai prodotti che troviamo al supermercato o su Amazon), l’adozione di buoni processi, e una gestione competente;
-
dobbiamo anche fugare un concetto gravemente forviante: il recupero ed il ripristino dei file contenuti in un backup non comportano che il sito torna in vita.
C’è da considerare il ripristino del database, che vedremo qui sotto. I dati del database devono essere sincroni con il momento di backup. Inoltre dobbiamo ripristinare il backup all’interno di un web server compatibile e che riproduca lo stesso ambiente software presente al momento della creazione del backup.
Ad esempio il ripristino dal backup del database MariaDB in PostgreSQL non ripristina correttamente i dati malgrado entrambi parlino l’SQL.
Il ripristino dei file del CMS in un web server che usi come web root il path /srv/html non permette il funzionamento al CMS che era installato nel path /var/www/html; il web server dovrebbe avere le stesse configurazioni ed i medesimi path oppure va configurato in modo totalmente compatibile con quello di origine.
Database:
-
iniziamo da una premessa generale. Anche se molti database parlano SQL, ciascuno gestisce i dati in modo diverso. Inoltre per tutti i database non possiamo copiare i file che costituiscono la base dati, ma possiamo estrarre i dati ed esportarli in un formato legacy come l’SQL, il CSV, ecc…
Pertanto teniamo ben presente che l’export e l’import richiede una procedura che si basa su file intermedi.
Di converso questo significa che non possiamo salvare alcuni oggetti come gli indici. Al momento del ripristino le istruzioni SQL disporranno che il database ricrei questi oggetti, mentre il ripristino dei dati contenuti nelle tabelle comporta che il database ricodifica tutte le entry;
-
come si può capire dalla premessa generale fatta al punto sopra il database lo salviamo tramite un’operazione di estrazione che ci permette di avere i dati in un formato intermedio.
L’estrazione dipende dal database in uso: mysqldump, mariadb-dump, pg_dump per gli RDBMS che abbiamo citato e usato prima. Possiamo usare le istruzioni native SQL da DBeaver, PhpMySQL o altro tool SQL.
In ogni caso otteniamo file lunghi (e spesso molto voluminosi) di testo base contenenti istruzioni SQL. Normalmente si comprimono e inseriscono o allegano al backup dei file dei siti;
-
un ulteriore aspetto da conoscere sono le relazioni tra le tabelle. Tradizionalmente le relazioni erano nelle query che il CMS inoltra al database. Alcuni database salvano internamente le relazioni come anche procedure o script. Insomma: anche se tutti capiscono e parlano SQL i database sonno molto diversi e il salvataggio in un formato legacy comporta:
-
potenziale perdita di meta-informazioni;
-
i dati estratti non sono significativi-usabili se non vengono ri-inseriti nel CMS (cioè: possiamo non trovare l’articolo come un record del database);
-
i file vanno ripristinati all’interno delle stesso tipo di database;
-
-
altra piccola, ma insidiosa, particolarità è la codifica dei caratteri. Questo significa che il ripristino dei dati prevedono che il database di destinazione sia stato creato con la stessa tipologia di codifica (es.: latin1, UTF8, UTF16, ecc..);
-
ultimo elemento da conoscere riguarda MySQL e MariaDB. A differenza della maggioranza degli RDMS i database MySQL e MariaDB hanno motori diversi nel loro cuore: MyISAM, InnoDB, Memory, XtraDB, ecc..
Questo significa che il restore, per produrre dati corretti, necessita di tabelle associate allo stesso motore.
Questo aspetto specifico di MySQL e MariaDB non trova una controparte speculare in PostgreSQL o altri RDMS.
Il backup è un copia semplice dei file, ma già da queste caratteristiche generali vediamo che non è una copia facile.
6.2. Backup: tipologie e frequenza
Il mondo dei backup introduce altri tre elementi rilevanti: tipologia, snapshot e frequenza.
6.2.1. Tipologia
Iniziamo dalla tipologia. Per capire immaginiamo di fare oggi il backup dei file del nostro CMS e di rifare la stessa operazione tra una settimana. La quasi totalità dei file saranno gli stessi. Ragionevolmente avremmo qualche file nuovo che potrebbero essere le foto degli artico aggiunti tra i due momenti di backup. In questa situazione semplice è un eccesso di zelo fare entrambe le volte una copia completa. La seconda volta è più ragionevole fare la copia solo dei file nuovi. Questo significa fare un backup molto più rapido e risparmiare molto spazio.
Un secondo caso da prendere in considerazione sono i file modificati. Ipotizziamo che il nostro CMS abbia un file di testo con i log degli accessi. Immaginiamo di fare come sopra il backup oggi ed un secondo backup a distanza di una settimana. Come detto sopra possiamo salvare solo file nuovi. Ma in questo caso dobbiamo salvare anche il file di log perché sarà cresciuto e, pur avendo lo stesso nome, sarà diverso.
Si intuisce che possiamo realizzare tipi diversi di backup: backup completo, incrementale e differenziale:
-
backup completo: significa la copia integrale di tutti i file senza alcuna condizione o filtro;
-
backup incrementale: significa la copia di tutti i nuovi file non presenti nel precedente backup;
-
backup differenziale: significa la copia di tutti i file che sono cambiati rispetto al precedente backup.
6.2.2. Snapshot
Dopo la tipologia di backup è opportuno introdurre un elemento insidioso. Come spiegato è necessario del tempo per creare il backup. Più grande è il sito (o i siti) maggiore è il tempo necessario. Pertanto possiamo incorrere in situazioni dove avvengono modifiche nei file o nel database durante il backup. Si tratta di una situazione difficile da gestire. Una soluzione è il blocco temporaneo del sito e dei servizi, ma questo introduce un disservizio che può essere molto antipatico. Una seconda soluzione può essere nella generazione di snapshot ed il backup viene fatto nei dati dentro lo snapshot. Questa tecnica si basa sulla capacità di alcuni file system e sistemi operativi di congelare un istante dell’hard disk senza bloccare l’attività e permettendo l’accesso ai dati presenti nello snapshot e successivamente di cancellarlo. Il processo è poco impattante in termini di calcolo e performance, ma richiede un accesso sistemistico e non tutti i server supportano gli snapshot.
Possiamo considerare che gli snapshot sono in se stessi un backup, ma comportano dei problemi. In primis è una meta-archiviazione dello stato dei bit del disco che appesantisce il disco e che crea un progressivo decremento delle performance (infatti più tempo passa, più sono le differenze che vanno salvate). Poi si tratta del congelamento dell’intero disco, non possiamo isolarlo a una sola directory, né distribuirlo su più utenti e ciascuno gestisce una parte specifica del disco.
In conclusione gli snapshot sono una fantastica tecnologia, ma non sono un backup, ma possono aiutare nel creare backup.
6.2.3. Frequenza
Non esiste una tempistica ideale, corretta e universale, ma abbiamo delle buone pratiche da tenere presenti per avere una corretta politica dei backup:
-
il backup va eseguito nel momento di minor carico e minor accesso. Idealmente nel cuore della notte, ma nel caso di siti web in produzione che hanno visite da tutto il mondo non esiste una fascia oraria ideale. Potenzialmente tutte le ore sono momento di accesso;
-
la messa in produzione del sito è il primo momento di backup completo;
-
usando i CMS, o soluzioni con architettura analoga, possiamo investire su un backup frequente del solo database, magari giornaliero, e periodico uno incrementale e un full con frequenza mensile o bimestrale;
-
è buona pratica fare un backup completo prima di ogni intervento massivo o potenzialmente rischioso (come aggiornamenti, aggiunta di funzionalità, cambio del template, ecc…);
-
in fine è bene scegliere le frequenze e tipologie di backup alla luce della frequenza dell’aggiornamento dei contenuti e/o delle attività degli utenti (nel caso di siti attivi come shopping online, forum, blog con possibilità di commenti, ecc...).
A valle di tutto ciò si può guardare a una pianificazione come segue:
-
backup completo alla messa in produzione, prima di ogni intervento impattante-pericoloso e post intervento finiti i test di verifica;
-
backup settimanale del database e differenziale;
-
backup quindicinale incrementale;
-
backup completo bimensile.
6.3. Backup in esecuzione
Esistono diverse soluzioni. In linea di principio non è una politica saggia una soluzione di solo backup cloud.
Nel caso di servizi acquistati su provider spesso offrono soluzioni di backup con un piccolo costo aggiuntivo; sono da prendere in considerazione con la precauzione che i file fanno anche copiati in locale, su un proprio supporto di memoria (hard disk esterno, pendrive, ecc...).
Nel caso in cui abbiamo la possibilità di gestione del server (come abbiamo fatto in questo manuale) possiamo usare uno strumento tradizione come tar, o il potente rsync o adottare software più completi come Amanda o Bacula.
6.3.1. Device
In primo luogo abbiamo bisogno di un supporto di memoria di massa diverso dal web-server. Inoltre l’ideale è che i singoli supporti (dischi, cassette, ecc…) si possano asportare.
Una politica che ha dimostrato la sua bontà è l’adozione di un set di supporti: metà sono nel sistema di backup, metà in cassaforte in un altro edificio. Periodicamente i supporti vengono girati. La bontà della soluzione si scontra con due problemi:
-
le quantità di dati che richiedono supporti molto capienti. L’esplosione delle dimensioni dei dati rende eccessivamente grande (e costoso) l’adozione di un adeguato set di supporti;
-
il secondo problema è il lavoro umano: ripetitivo, delicato e costoso.
La soluzione con due set di supporti resta molto valida, oggi, solo per server di piccole dimensioni e per server privati.
I noti NAS (sistemi di storage su disco) possono essere usati come device di backup. Esistono versioni per tutte le tasche e per molti casi d’uso. Va considerato, innanzitutto, che i modelli piccoli hanno schede di rete che possono essere lente per archiviare backup grandi. Inoltre molti modelli hanno un solo alimentatore rendendoli vulnerabili ai guasti che lo possono riguardare. Se guardiamo ai modelli entry level non sono in formato rack mount.
Sul mercato server esistono diverse appliance dedicate al backup: sono dispositivi rack mount che si alloggiano negli armadi dei server. Connessi direttamente alla fibra del CED o ai server sono particolarmente flessibili. Il controllo remoto, normalmente fatto dal software stesso del backup, permette di automatizzare tutta l’attività. Le tradizionali tape library fanno automaticamente anche la rotazione delle cassette.
Il punto debole di questa soluzione sta nell’ubicazione: le appliance ed i device sono nello stesso luogo dei server. In caso di un evento grave (un fulmine, un incendio, un terremoto, ecc…) insieme ai serve perdiamo anche i backup.
Una mitigazione di queste debolezze la introduce la rete. Ad esempio collegando due edifici tramite una fibra, con schede veloci (come quelle da 800G), possiamo trasferire da un edificio all’altro i backup velocemente.
La grande quantità di dati, nel caso di server e server farm (=cloud) limita la bontà di queste soluzioni che comunque sono soluzioni molto costose.
L’adozione della rete apre le porte all’uso del cloud per il backup. Ci sono più provider che vendono soluzioni di backup online. A conti fatti sono convenienti e normalmente offrono un buon software. Dobbiamo però considerare la lentezza di internet: trasferire qualche giga oggi non è particolarmente lungo, ma spostare set interi di dati via internet può richiedere tempi molto lunghi. Inoltre dobbiamo considerare l’ipotesi che la connessione non sia disponibile, o sia troppo lenta, o discontinua… Tutte situazioni che inficiano la bontà di un backup basato solo sul cloud. Nascosto, ma molto rilevante, c’è anche il problema della sovranità dei dati quando il server fisico si trova in continenti-stati diversi dal proprio con normative diverse…
Insomma: in ultima analisi non è una buona soluzione se la immaginiamo come soluzione unica o principale.
Per tornare agli obiettivi di questo manuale e immaginando uno scenario didattico con un dataset contenuto (immaginiamo qualche centinaio di GB) possiamo guardare con interesse a una soluzione basata su una tipe library o una con hard disk estraibili su bus veloci (i vecchi SATA, o un SAS, un NVMe, ecc…).
La rotazione dei supporti la possiamo gestire manualmente o tramite automazione software. La soluzione sarà abbastanza economica e sopratutto funzionale. Se optiamo per una rotazione manuale dei supporti l’effort umano aggiuntivo sarà contenuto.
6.3.2. Tar
Nato per archiviare su nastro magnetico in ambiente Unix, è diventato successivamente uno elemento dello standard Posix, motivo per cui è uno standard di fatto per tutti gli ambienti Unix e *nix come Linux e Mac.
Come software a se non prevede nativamente una gestione di tutto il ciclo di vita dei backup. Restando su obiettivi piccoli possiamo creare qualche script che lancia tar, magari comprimendo i file di output e salvandoli su un disco rimovibile. Il restore, di un file o dell’intera collezione, sarà una procedura manuale.
Cercando sarà facile trovare soluzioni basate su script che creano, in modo semiautomatico, i backup.
A titolo d’esempio qui di seguito degli script di backup basati su tar . Gli script creeranno file compressi tramite lbzip2 che sfrutta tutti i core ed i thread del processore accelerando notevolmente i tempi di compressione. I file generati vengono messi nella directory /home/backuser/backup/daily , accessibile via SFTP per il download.
Gli script si ispirano alla guida di Tony Teaches Tech «How to Backup Daily, Weekly, and Monthly with tar, rsync, and cron» https://tonyteaches.tech/rsync-backup-tutorial .
Iniziamo installando l’utility lbzip2
sudo apt install -y lbzip2
aggiungiamo l’utente backuser con password MiaBak73Pass##webSrv per il download via SFTP
sudo useradd -m -s /usr/sbin/nologin backuser
passwd backuser
New password: MiaBak73Pass##webSrv
Retype new password: MiaBak73Pass##webSrv
passwd: password updated successfully
NB 1: abbiamo creato un utente che non può loggarsi ( -s /usr/sbin/nologin ), ma ha una password;
NB 2: per motivi di migliore sicurezza è bene che il client SFTP si colleghi tramite certificato invece che password.
Creiamo le directory dei backup
sudo mkdir -p /home/backuser/backup/daily
sudo mkdir -p /home/backuser/backup/weekly
sudo mkdir -p /home/backuser/backup/monthly
sudo chown backuser:backuser -R /home/backuser/backup
Aggiungiamo l’utility di compressione lbzip2
sudo apt install lbzip2
Passiamo ora a creare i tre script di backup. Poi automatizzeremo l’esecuzione tramite cron.
-
Creiamo i file degli script rendendoli eseguibili
sudo touch /usr/local/sbin/bak-daily.sh
sudo touch /usr/local/sbin/bak-weekly.sh
sudo touch /usr/local/sbin/bak-monthly.sh
sudo chmod 700 /usr/local/sbin/bak-daily.sh
sudo chmod 700 /usr/local/sbin/bak-weekly.sh
sudo chmod 700 /usr/local/sbin/bak-monthly.sh
-
editiamo /usr/local/sbin/bak-daily.sh
sudo nano /usr/local/sbin/bak-daily.sh
-
e popoliamolo come segue
#!/bin/bash
#
# backup GIORNALIERO
# /usr/local/sbin/bak-daily.sh
# creazione del backup dei file
tar -I lbzip2 -cf /home/backuser/backup/daily/backup-$(date +%Y%m%d).tar.gz --absolute-names /var/www/html
# creazione del backup dei database
mariadb-dump --all-databases | lbzip2 -c > /home/backuser/backup/daily/backup-$(date +%Y%m%d).sql.bz2
# correzione PERMESSI
chown backuser:backuser -R /home/backuser/backup/daily
# rimozione dei backup più vecchi di 7 giorni
find /home/backuser/backup/daily/* -mtime +7 -delete
-
editiamo /usr/local/sbin/bak-weekly.sh
sudo nano /usr/local/sbin/bak-weekly.sh
-
e popoliamolo come segue
#!/bin/bash
#
# backup SETTIMANALE
# /usr/local/sbin/bak-weekly.sh
# creazione del backup dei file
tar -I lbzip2 -cf /home/backuser/backup/weekly/backup-$(date +%Y%m%d).tar.gz --absolute-names /var/www/html
# creazione del backup dei database
mariadb-dump --all-databases | lbzip2 -c > /home/backuser/backup/daily/backup-$(date +%Y%m%d).sql.bz2
# rimozione dei backup più vecchi di 31 giorni
find /home/backuser/backup/weekly/* -mtime +31 -delete
-
editiamo /usr/local/sbin/bak-monthly.sh
sudo nano /usr/local/sbin/bak-monthly.sh
-
e popoliamolo come segue
#!/bin/bash
#
# backup MENSILE
# /usr/local/sbin/bak-monthly.sh
# creazione del backup dei file
tar -I lbzip2 -cf /home/backuser/backup/monthly/backup-$(date +%Y%m%d).tar.gz --absolute-names /var/www/html
# creazione del backup dei database
mariadb-dump --all-databases | lbzip2 -c > /home/backuser/backup/daily/backup-$(date +%Y%m%d).sql.bz2
# rimozione dei backup più vecchi di 365 giorni
find /home/backuser/backup/monthly/* -mtime +365 -delete
-
invochiamo l’editor crontab per root in modo che gli script vengono eseguiti al di sopra di ogni restrizione
NB: questo approccio garantisce una esecuzione senza problemi, ma non è una buona scelta di sicurezza
sudo crontab -e
-
e inseriamo le seguenti stringhe
15 0 * * * /usr/local/sbin/bak-daily.sh
30 0 * * 1 /usr/local/sbin/bak-weekly.sh
45 0 1 * * /usr/local/sbin/bak-monthly.sh
Abbiamo completato un semplice sistema di backup che copia tutti i file, estrae tutti i database (eccetto mysql dove sono salvate le configurazioni, i permessi, gli utenti e le password), comprime tutti i backup al volo, gestisce la conservazione con una rotazione giornaliera, settimanale, mensile, annuale e permette lo scaricamento remoto tramite un accesso sicuro SFTP.
6.3.3. Rsync
rsync è uno storico programma di sincronizzazione di directory e file. Nato in ambiente *nix sono disponibili porting nativi per i principali sistemi operativi. I sorgenti sono disponibili per tutti garantendo portabilità e mantenimento.
Il programma è molto interessante perché è costruito intorno alla logica delta: si sincronizzano le differenze. Adottando questo principio si minimizzano i trasferimenti offrendo un’alta performance. L’uso su rete impiega la porta TCP 873.
accanto alla logica delta il programma permette diverse logiche per attuare la sincronizzazione. Come programma autonomo è facile integrarlo all’interno di script, anche in ambiente Windows magari integrandolo nei potenti script PowerShell.
Per molti utenti sarà una sicuramente un’importante difficoltà l’assenza di una finestra grafica per l’invocazione. Comunque esistono applicazioni di terze parti che offrono potenti e comode finestre grafiche. Da considerare anche la complessità delle opzioni: la disponibilità di tante possibilità avanzate e di dettaglio creano complessità e richiedono competenze superiori al livello medio. Anche la sua struttura client-serve è una difficoltà aggiuntiva per utenti alle prime armi.
Come per tar anche rsync non prevede nativamente una gestione di tutto il ciclo di vita dei backup. Possiamo gestire la mancanza tramite script come abbiamo fatto prima con tar.
Per un’implementazione è sufficiente googlare e la rete offre diversi esempi pronti all’uso.
Una piccola miniera di informazioni e guide è il sito ufficiale: https://rsync.samba.org .
Allo scopo di facilitare la ricerca riportiamo alcune risorse-esempi di qualità presenti in rete:
-
Backup automatico con rsync via ssh,
https://guide.debianizzati.org/index.php/Backup_automatico_con_rsync_via_ssh -
Learning Rsync,
https://docs.rockylinux.org/it/books/learning_rsync/01_rsync_overview/ -
Using rsync to back up your Linux system,
https://open source.com/article/17/1/rsync-backup-linux -
Come usare rsync, esempi pratici,
https://devdev.it/comando-rsync-esempi-pratici-144/ -
Rsync: cos’è e come usarlo per creare backup dati sincronizzati in cartelle locali e remote,
https://www.cybersecurity360.it/soluzioni-aziendali/rsync-cose-e-come-usarlo-per-creare-backup-dati-sincronizzati-in-cartelle-locali-e-remote
6.3.4. Amanda
Amanda ( https://www.zmanda.com ) è vero software di backup di rete. Disponibile per i principali sistemi operativi è concepito per backuppare PC, singoli server fino a grandi server farm anche geograficamente distribuite. Il suo punto di forza è la centralizzazione, l’automazione e l’indipendenza sia dal sistema operativo, sia dall’hardware e anche dal media di conservazione dei backup.
Tra i punti di forza c’è la doppia disponibilità: versione in totale open source e versione aziendale distribuita con il nome Zmanda. la versione open source è di serie nei repo di tutte le principali distribuzioni Linux. Inoltre Amanda prevede tutto quello che serve ad un moderno, efficiente e sicuro sistema di backup di rete.
L’implementazione è un’attività che richiede un po’ di spiegazioni, un po’ di studio e un po’ di tempo. Insomma: non possiamo ridurla a due semplice pagine d’esempio. Qui di seguito la rappresentazione dell’architettura globale di Amanda o Zmanda per offrire un’idea della complessità e delle potenzialità.
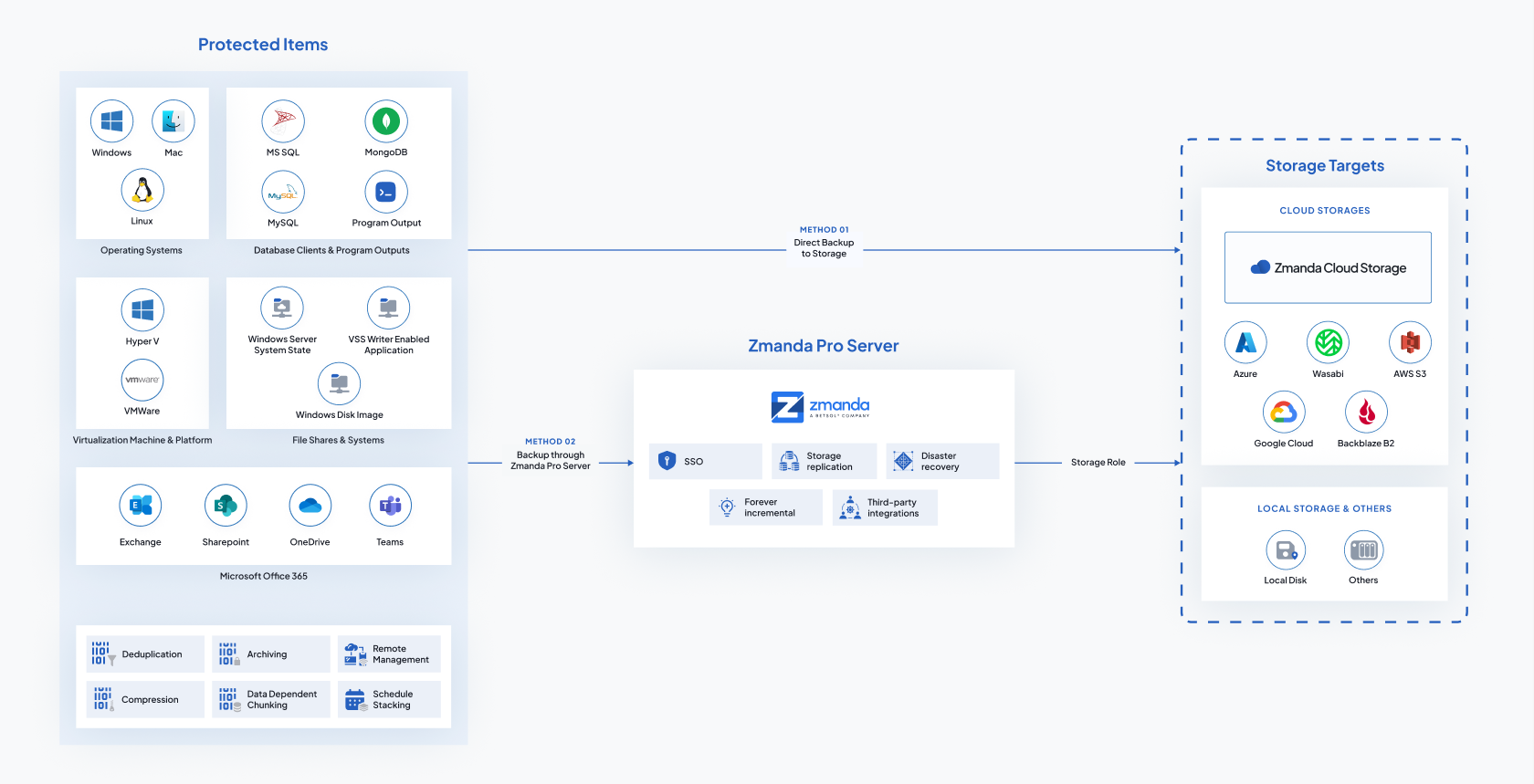
Figura 37: Amanda e Zamanda: architettura generale
Per l’implementazione rimandiamo alla documentazione ufficiale: esaustiva e ben fatta sia per la versione community, sia per quella enterprise. In caso di bisogno sono disponibili sia sottoscrizioni, sia aziende che offrono il servizio di installazione-configurazione e/o l’assistenza.
Qui di seguito alcuni link, a partire da quelli del prodotto, quelli della documentazione e qualche guida:
-
Amanda,
https://www.amanda.org/ -
Zmanda,
-
Zmanda Knowledge Base,
-
Welcome to the Zmanda Pro Documentation,
-
Amanda wiki,
-
GitHub Zmanda,
6.3.5. Bacula
Bacula ( https://www.bacula.org ) è un software di backup di rete come Amanda. Si tratta di un software di tipo enterprise, che permette una gestione totalmente centralizzata, automatizzata e securizzata.
Permette di tenere sotto backup PC, singoli server e server farm singole o geograficamente distribuite.
Accanto alla versione open source c’è la versione enterprise con servizi di sottoscrizione, mantenimento e servizi di assistenza rintracciabili al sito ufficiale: https://www.baculasystems.com .
La grande potenzialità si accompagna a una complessità importante.
Bacula, forse, a differenza di Amanda e Zmanda, offre qualcosa in più anche nella versione solo open source, come, ad esempio, l’interfaccia grafica e l’integrazione nativa con alcuni tool di gestione sistemistica.
L’implementazione è un’attività che richiede un po’ di spiegazioni, un po’ di studio e un po’ di tempo. Insomma: non possiamo ridurla a due semplice pagine d’esempio. Qui di seguito la rappresentazione dell’architettura globale di Bacula per offrire un’idea della complessità e delle potenzialità.
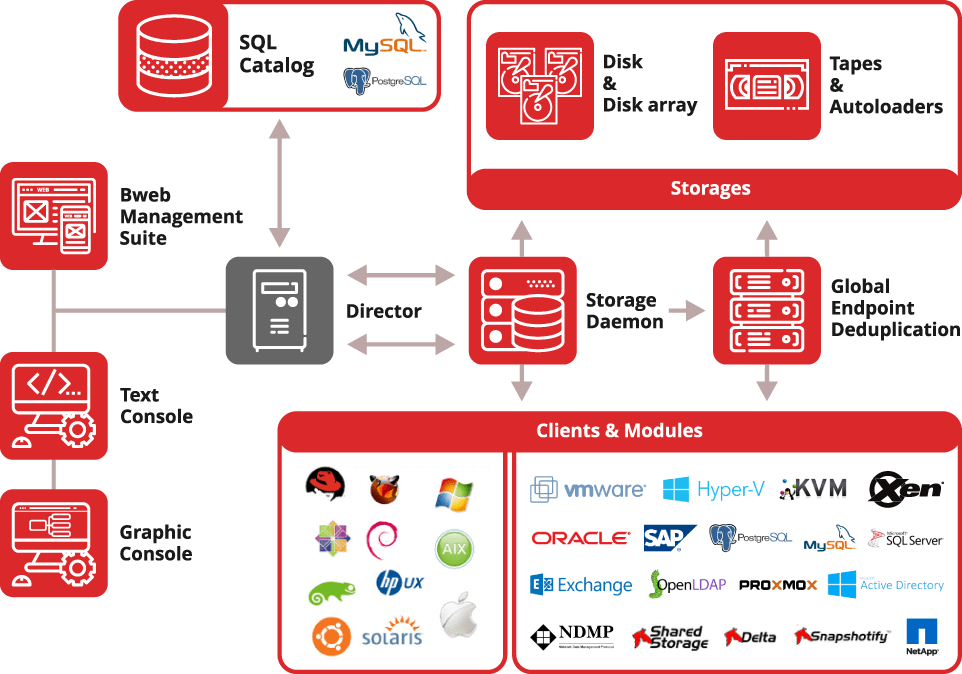
Figura 38: Bacula: architettura generale
Per l’implementazione rimandiamo alla documentazione ufficiale: esaustiva e ben fatta sia per la versione community, sia per quella enterprise. In caso di bisogno sono disponibili sia sottoscrizioni e aziende che offrono il servizio d’installazione-configurazione e/o l’assistenza.
Segnaliamo il tool Baculum ( https://www.bacula.lat/community/baculum-9-graphical-bacula-configuration-administration-and-api/ ). Si tratta di un completo, potente e comodo software di gestione e controllo di Bacula via web.
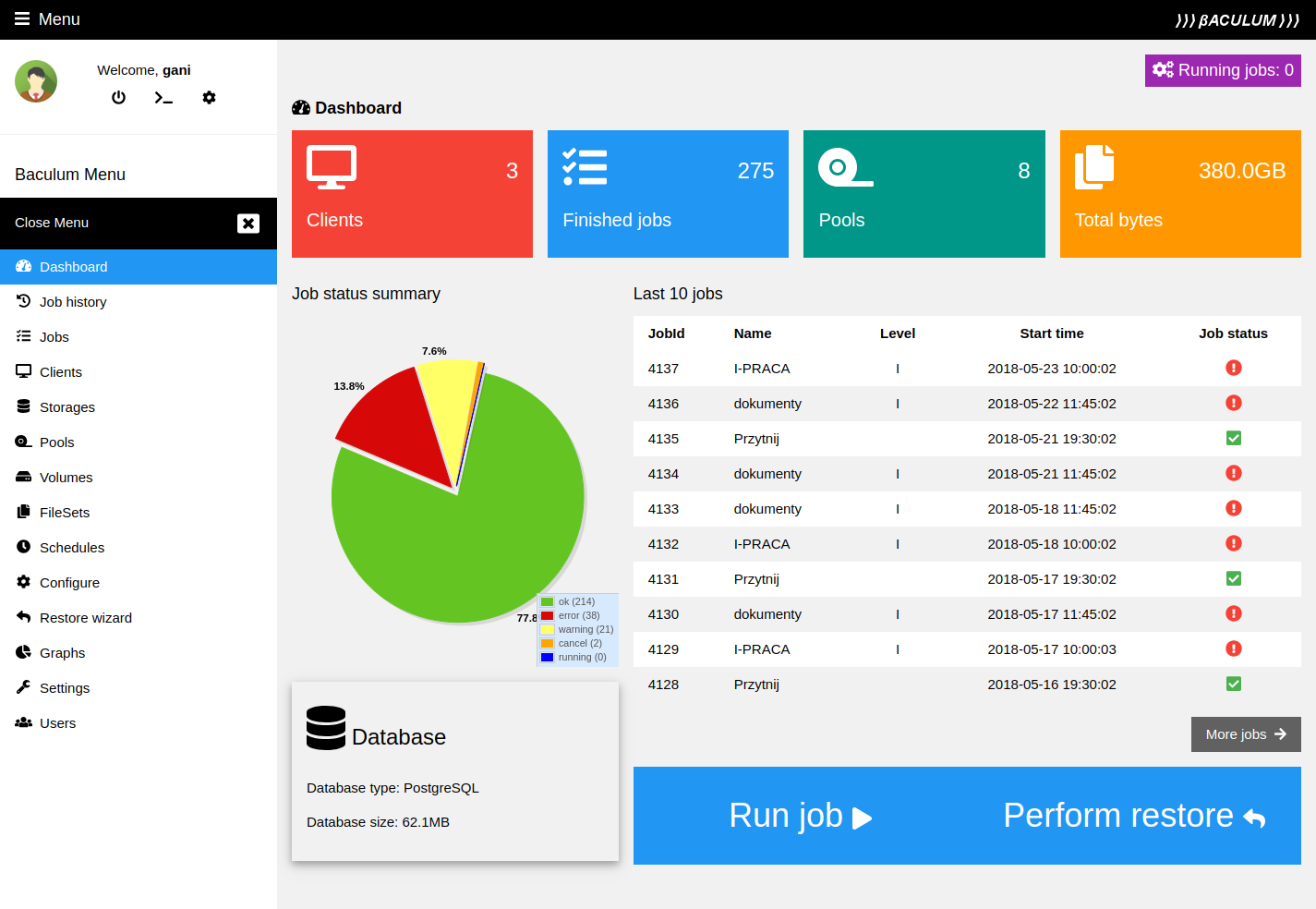
Figura 39: Schermata di Baculum
Qui di seguito alcuni link, a partire da quelli del prodotto, della documentazione e qualche guida:
-
Bacula Systems - backup software for modern data center,
-
The best open source backup software for Linux,
-
Bacula® Manuals,
-
How to install and configure Bacula,
https://ubuntu.com/server/docs/how-to-install-and-configure-bacula
-
How I use the Bacula GUI for backup and recovery,
https://open source.com/article/22/5/baculum-open source-backup
6.4. Backup: la conservazione
La conservazione dei backup si organizza fondamentalmente su due elementi:
-
tempo: rotazione e tempo di ritenzione dei device;
-
luogo: sito dello storage e/o cloud.
Dobbiamo, però, aggiungere subito un terzo elemento di natura discrezionale: importanza e rilevanza dei dati. A seconda dell’importanza di questi elementi si organizza tutto il resto.
Teniamo presente che la conservazione dei backup è un costo.
Completata questa piccola premessa ricordiamoci che abbiamo già affrontato, in parte, l’argomento.
6.4.1. Tempo
Per tempo dobbiamo pensare alla durata della disponibilità di una certa versione dei nostri file.
Con i moderni sistemi di siti web insieme ai file dobbiamo guardare soprattutto ai database in backend al sistema di sito e alle configurazioni dell’ambiente.
Idealmente possiamo pensare a 12 mesi massimi di conservazione.
Accanto al tempo dobbiamo valutare la frequenza di rotazione. Come visto sopra un buon approccio è:
-
copia giornaliera con ritenzione settimanale;
-
copia settimanale con ritenzione mensile;
-
copia mensile con ritenzione annuale.
6.4.2. Luogo
Anche questo argomento è già stato affrontato.
Il concetto centrale irrinunciabile è che il backup non risiede sul server e i supporti di memoria, che contengono i backup devono essere rimovibili.
Riproponiamo una riflessione sulla soluzione cloud diventata popolare, economica e, soprattutto, ci sgrava da diversi aspetti logistici. In realtà introduce diversi problemi a iniziare dalla sovranità sui dati, alla dipendenza dalla connessione internet e alle tempistiche eccessivamente lunghe per il completo trasferimento attraverso internet.
Se la soluzione cloud è ottima nel caso di piccoli server (che generano file di qualche giga), legati a servizi non critici, in tutti gli altri casi il cloud è positivo solo come device aggiuntivo.
Discorso leggermente diverso nel caso di una sottoscrizione ad un servizio di web hosting, dove, a fronte di una integrazione di contratto, possiamo avere il backup insieme all’hosting. In questo specifico caso abbiamo molti vantaggi ad avere tutto integrato. Dobbiamo pensare e decidere circa la sovranità dei backup (quindi se averne una copia in locale e con quale frequenza farli) e l’eventuale gestione della migrazione di provider.
Per quest’ultima situazione (migrazione da un provider ad un altro) teniamo presente che possiamo trovarci con configurazioni dell’ambiente web-server diverse che rendono incompatibili i backup.
Dopo questa premessa (o promemoria) vediamo come gestire le copie fuori dal server.
Una soluzione intuitivamente semplice è dotare il server id un NAS. Accanto alla semplicità all’economicità dei NAS retail target dobbiamo considerare:
-
le interfacce di rete domestiche sono troppo lente per volumi importanti da backuppare. Già 100GB creano qualche problema;
-
i NAS comuni prevedono facilmente il cambio a caldo dei dischi, ma spesso non permettono di mettere un adeguato numero di dischi. Inoltre una volta estratti i dischi possono non permettere un accesso diretto ai file contenuti come, ad esempio, quando sono parte di un array RAID;
-
per avere una buona performance del NAS dobbiamo collocarlo nel CED dove si trova il web server creando il cortocircuito che un grave incidente nel CED (es.: un incendio) compromette anche il backup;
-
i NAS con caratteristiche che risolvono i limiti sopra hanno costi analoghi come i sistemi di storage.
Un’alternativa molto valida è l’adozione di uno storage:
-
possiamo immaginare ad un server con configurato come storage o a uno storage nativo. Entrambe le soluzioni possono risolvere i problemi sopra. Probabilmente un server configurato a storage permette, a parità di risultati, di spendere di meno;
-
uno storage ha costi decisamente superiori ad un NAS (eccetto i casi di NAS di alta fascia per CED);
-
dotati di interfacce di rete su fibra permette di avere transfer rate adeguati, rendendo funzionale il backup;
-
la vulnerabilità legata alla collocazione all’interno del CED è compensata dalla possibilità di estrazione e cambio dei dischi a caldo;
-
con una dotazione di questo tipo è facile integrare automaticamente un nodo mirror collocato in un diverso edificio (o diverso luogo geografico) mitigando ulteriormente il rischio legato ad incidenti gravi nel CED;
-
resta che i costi totali diventano rilevanti.
Ancora valide sono le tradizionali soluzioni basate su appliance tape library:
-
sono soluzioni poco note, ma largamente consolidate;
-
sono ben integrate con tutto l’ecosistema di backup;
-
abbiamo cassette a nastro di buona capienza;
-
permettono la rotazione delle cassette (a titolo d’esempio: una muta nel caricatore della tape library e una in cassaforte);
-
sono macchine completamente automatizzate;
-
però sono dispositivi lenti sia in scrittura che in ripristino.
Per i media che mettiamo in cassaforte:
-
ovviamente deve essere un luogo sicuro,
-
è bene che sia in condizioni ambientali controllate (raffrescato, a umidità controllata, non polveroso, senza campi magnetici, senza raggi solari diretti sui media e possibilmente con un sistema di log degli accessi e uscite).
Infine ricordiamoci dei grandi limiti dei supporti di memoria:
-
le scritture magnetiche deteriorano con il tempo. Nastri e dischi vanno copiati e dismessi prima del tempo medio di persistenza del dato magnetico;
-
tutte le tecnologie che abbiamo hanno una durata prestabilita. I backup vanno conserva meno del tempo medio di vita del supporto;
-
le tecnologie quando diventano obsolete impediscono l’utilizzo dei supporti. Pertanto bisogna cambiare tutto prima che una tecnologia diventi obsoleta.
6.5. Backup VS disaster recovery
Il backup ed il disaster recovery sono cose diverse, anche se complementari:
-
il disaster recovery è la copia delle informazioni necessarie per ripristinare il PC o il server o il cellulare;
-
il backup è una copia dei dati.
Obiettivo del disaster recovery e di ripristinare la funzionalità della macchina (pc, server o cellulare) e dei servizi, ma non di offrire il ripristino dei dati.
Obiettivo del backup è di ripristinare i dati, ma non la funzionalità della macchina e dei servizi.
Pertanto le due pratiche funzionano a reciproco completamento.
Nel caso di un web server in produzione è importante (e necessario) avere entrambi, averli aggiornati e avere gli operatori capaci di effettuare sia il recovery, sia il restore.